
Single vs Multi-Head Attention
Attention series: 9 of 11

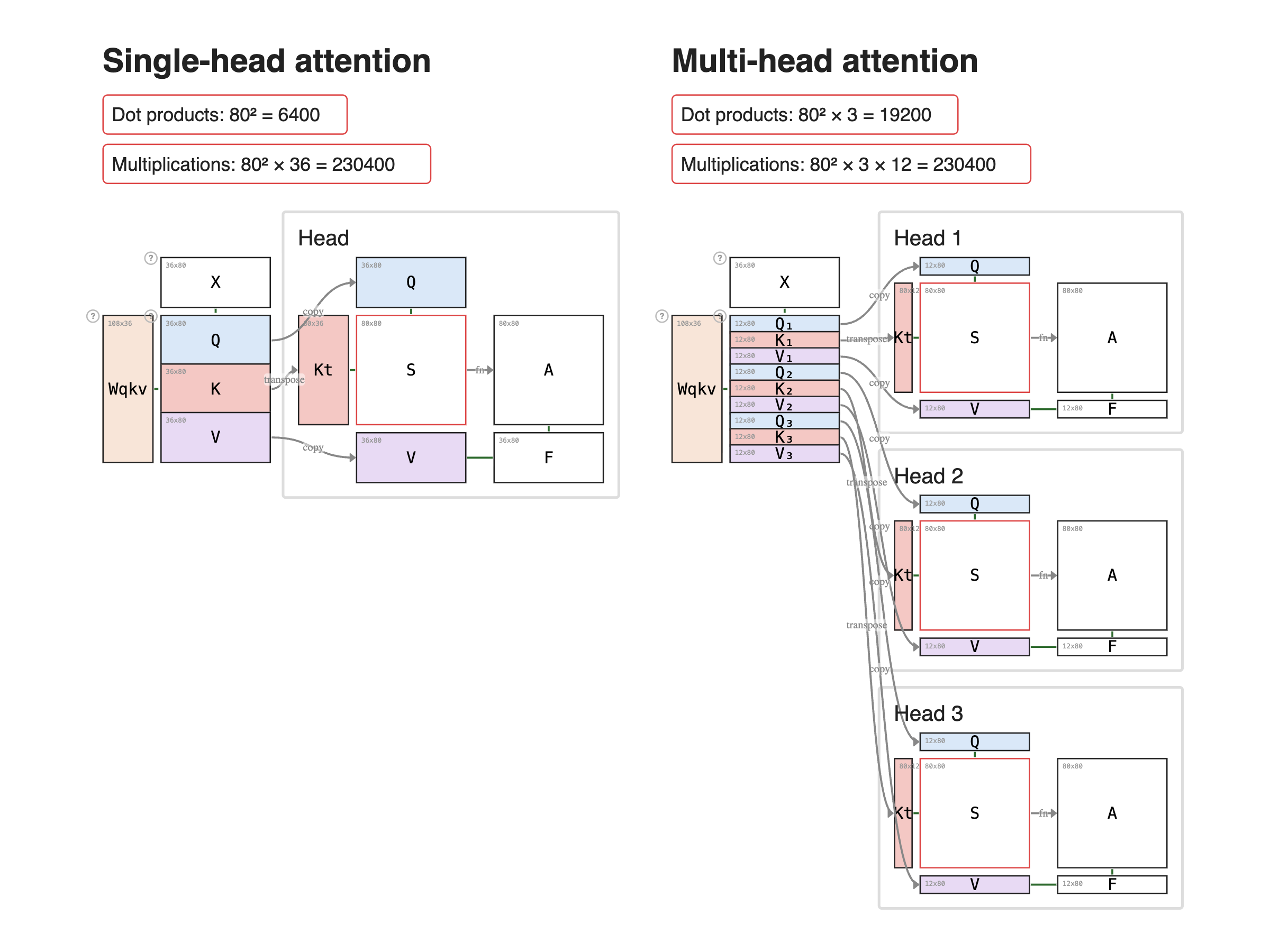
The most important fact about multi-head attention is that it has the same parameter count as single-head attention. The difference is purely structural: the same total Wqkv weights, partitioned into smaller q–k–v triples.
Look at the two diagrams below. Both Wqkv matrices have the same height: the same number of weight rows, the same number of parameters. What changes is how that single tall block is sliced.
Left. One head. The full Wqkv produces one big QKV: a tall Q (36 rows), a tall K, a tall V. One scoring computation runs over those full-width tensors.
Right. 3 heads. The same-height Wqkv is sliced into 3 smaller q–k–v triples, each 12 rows tall. 3 scoring computations run in parallel, each a thinner version of the left.
The compute trade-off (kind of). Same Wqkv weights. Multi-head runs the attention scoring S = Kᵀ × Q once per head, so the dot-product count multiplies by H.
Single-head: seq × seq = 80² = 6400 dot products
Multi-head: seq × seq × H = 80² × 3 = 19200 dot products (3×)
But each multi-head dot product is narrower: its inner dimension is head_dim instead of H × head_dim. When you count actual scalar multiplications, the totals are equal:
Single-head: seq² × (H × head_dim) = 80² × 36 = 230400
Multi-head: seq² × H × head_dim = 80² × 3 × 12 = 230400
Same total work, split across H specialized questions instead of one broad one.